In the course Software and Game Localization, our team proudly localized an app based on Android system through Android Studio. The game is called Patolli, which is derived from one of the oldest games in America. The game board consists 52 squares in X shape and there would be two players with 4-6 markers. They will roll the dice in turn and determine how many steps they can move the markers. The winner will be the one who can get all markers from one end of the queue to the other.
We begin the localization with assets analysis, followed by the i18n and l10n process, and a play test to make sure the game is consistent in different devices.

Here are
Click the links below to view the game before and after localization into Chinese.
Internationalization
After getting the assets, we played the game and quickly located the strings in the source codes. The texts in the pop-up windows are located in java files, and the static UI texts are found in xml files, which majorly deal with the UI layouts. In order to prepare for localization, our team worked on the strings and make them internationalizable by replacing strings with @string/name-of-string in xml files and used R.string.name-of-string to replace strings in the java files. However, the second practice proved to be problematic.
After some research, we found out that R.string is defined as an integer and we need more methods to extract the content in the string. There are three ways to get the content. First one is using getString() or getResources().getString() wrap the integer. The second one is to use getResources().getText(R.string.name).toString() to wrap the string. In this method, the getText function gets the texts with styles, thus we need a toString method to return the actual string. The third method is use String.valueOf(R.string.name) to wrap string. This is a method autho-suggested by Android Studio when it detected our errors.
After wrapping the strings, we listed all strings with their keys in a strings.xml file, where we also commented the sections of the strings so to provide a clear outlook just to make sure we include all strings(see image below). The strings file is now ready to be sent to translators for localization.
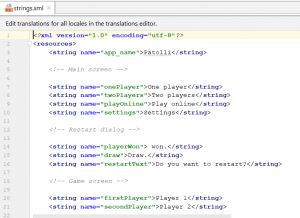
Sectioned Strings in strings.xml
Localization
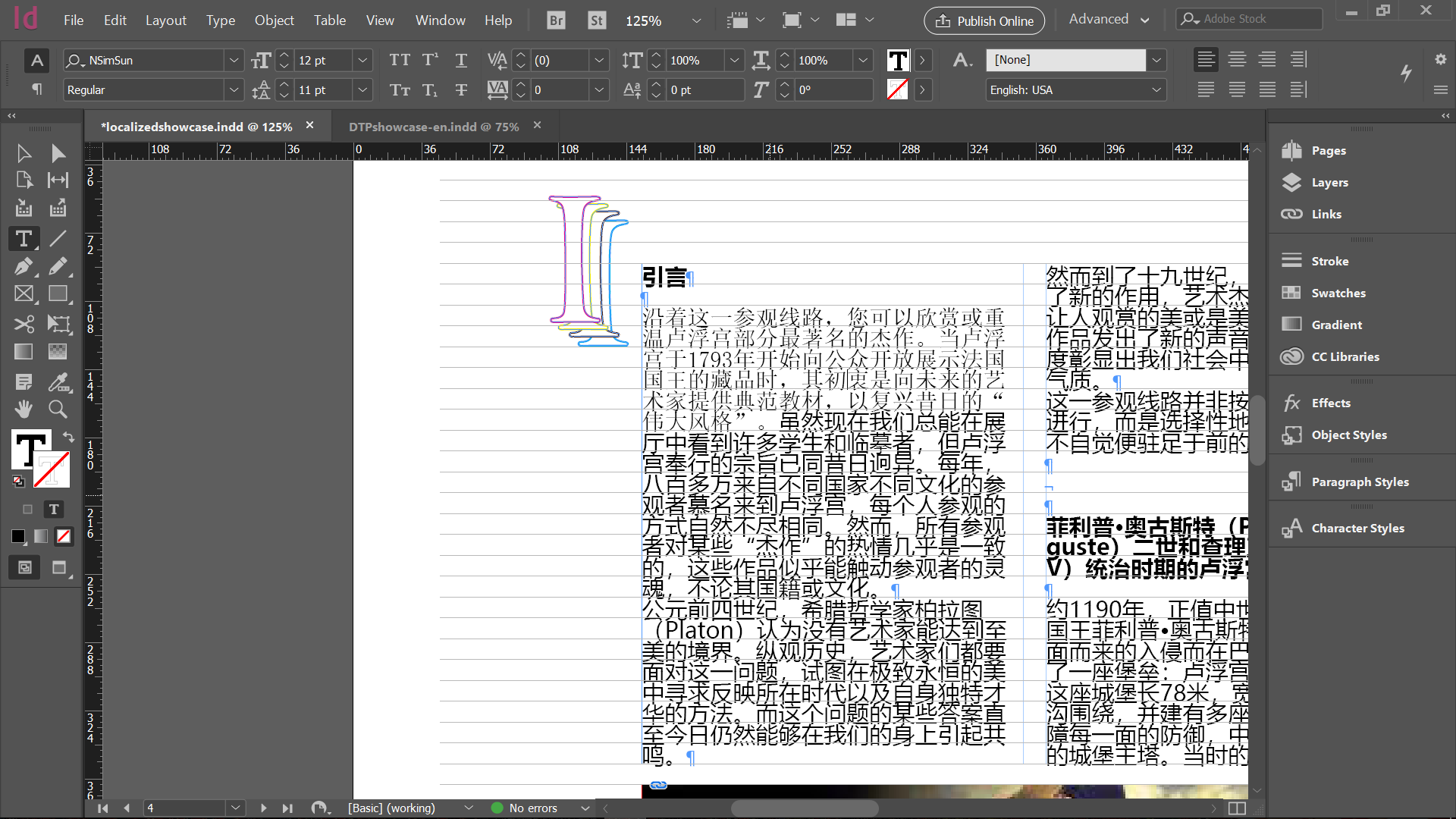
We used Memsource to translate the strings, downloaded the localized xml file and then placed it inside a values-zh folder we created under value folder. While we are editing the strings.xml file, we noticed that there is a built-in tool at Android Studio that can be used for small-scale games to localize their strings. The tool is called Translation Editor. After syncing the project, you can right-click the strings.xml file and choose to open it in Translation Editor.
![]()
Interface of Translation Editor in Andriod Studio
The above photos shows how the strings in the Editor will look like. You can add a locale simply by clicking the globe icon, and a locale folder will be automatically created under value folder. This automation can help you avoid naming the locales the wrong way. The plus and minus sign at the top left corner can be used to add or remove a key and associated translation. There are also filters at the top menu to help you sort all the strings by the key and locale. We think this tool shows great effeciency when dealing with small games with only a few strings.
Localization QA Testing
After all the localization is done, our team decided to test this game, particulary its function and display in different screen sizes. We choose 4” and 5” to see if there is any truncation or layout issues. Luckily, everything works well on different screens.











You must be logged in to post a comment.