Overview
This semester I dove deeper into the world of Computer-Assisted Translation (CAT). Building upon the general foundation I established during my first semester, this course provided the platform to gain greater insight into the different tools used by today’s language professionals.
Having been exposed to a wide range of CAT tools such as SDL Trados, Memsource, and memoQ, there is no question that CAT tools streamline the translation process and lower its associated costs. This coupled with ever-improving machine translation (MT) and the possibilities for an even faster translation process are undeniable. However, MT has not reached a point where it can be the sole form of translation, largely due to its inaccuracies vis-à-vis the nuances of human language.
Understanding the strengths of MT also requires one to understand its limitations. For one, there are several forms of MT: there is Rule-Based Machine Translation (RBMT), Statistical Machine Translation (SMT), Hybrid Machine Translation (HMT), and Neural Machine Translation (NMT). This semester I had the opportunity to work on a team with the goal of building a SMT engine. We learned first-hand the process and thinking needed to train our own SMT engine.
To train or not to train?
For starters how does SMT work? SMT uses statistical models that are based on the analysis of large volumes of bilingual text. Using these large volumes of bilingual text, it attempts to find correspondence between a word from the source language and a word from the target language. Depending on the subject matter text that is used to train the engine, the SMT is most suited for documents pertaining to the same subject.
In our first group meeting we brainstormed possible subjects and styles of documents that our SMT engine would translate. Given that we’d be using Microsoft CustomTranslator to build our SMT engine, we referred to the Microsoft Translator User Guide in helping us best determine how to select a topic. It stated the following:
“If your project is domain (category) specific, your documents, both parallel and monolingual, should be consistent in terminology with that category. The quality of the resulting translation system depends on the number of sentences in your document set and the quality of the sentences. “
We decided that TED talks provided us ample material that would be consistent in terminology among our source and target language. Below is our project overview.

Let the training begin!
In order to effectively manage our time and roles we came up with the following process steps:

The goal of this project was to meet the following criteria:
- Efficiency: PEMT roughly 30% faster than human translation.
- Cost: PEMT roughly 27.5% lower than human translation
- Quality:No critical errors in any category, no major errors for accuracy, fluency and terminology, and total score <= 15 per 1,000 words.
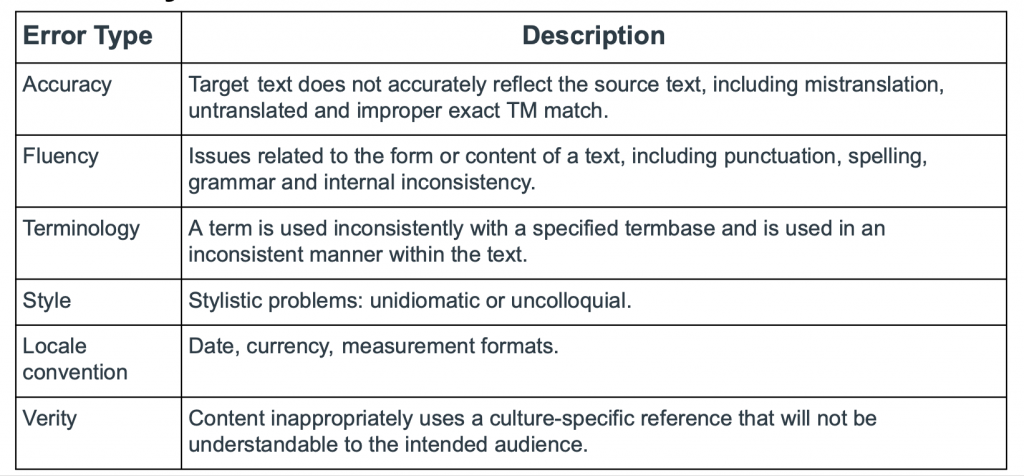

Images above display our quality metrics
As previously mentioned, MT is not infallible and thus requires editing, hence the PEMT (Post-Editing Machine Translation) shown within our Efficiency and Cost criteria. Apart from our own criteria, our training produced BLEU scores (Bilingual Evaluation Study). The BLEU score basically measures the difference between human and machine translation output. While a low BLEU score may indicate poor output quality (MT output vs. human ), it does provide a mechanism for improving the overall output (if the BLEU score increases over rounds of training).
Is TED worth training?
The short answer is no. Speeches are inherently filled with an array of lexical minefields, and the TED talks we used to build our corpora were no different. Simply put, SMT is not built for the translation of speeches. That being said, we did make interesting findings regarding our training, tuning, and testing data.
Data cleaning before training and tuning
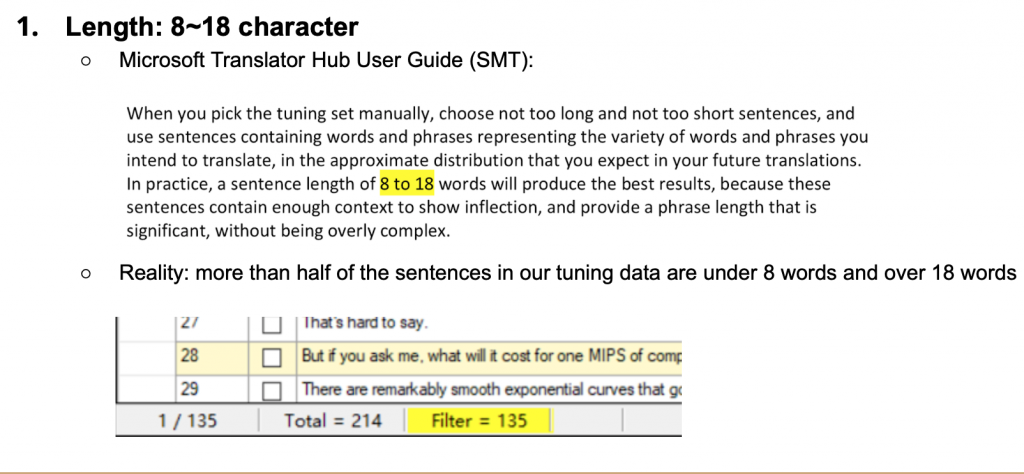
The Microsoft Translator Hub User Guide states “a sentence length of 8 to 18 words will produce the best results,” more than half our tuning data sentences were under 8 words and over 18 words. We believed shortening the sentence length in a new set of tuning data (500 words) would rectify this issue, however, the opposite occurred – our BLEU score dropped by 1.04.
Why?
- The general sentence length of the new tuning data set was too different from that of the previous training and tuning data
- Conclusion: Train with short sentences in the beginning and tune with short sentences!
Testing

The challenging nature of EN/ZH translation

Translating from English to Chinese is HARD. This especially true when dealing with speeches where language isn’t confined to structured or predicable patterns. The biggest drawback of SMT is that it does not factor in context, which is crucial to making sense of the TED talks we used. As you can see from our BLEU scores, significant improvements to our score were few and far between (see below). We conducted nine rounds of training and were unable to surpass or match our original BLEU score.

Conclusions
If you’re aiming for high-quality translations, be prepared to invest time and money training a SMT engine. SMT require a very large bilingual corpora. Not only does it need to be large, but also high-quality. Using low-quality data to train your engine will only lead to disappointment. While this project has reinforced my belief that SMT shouldn’t be used to translate speeches, I am not completely against the use of SMT with PEMT.
This is because after nine rounds of training and editing the raw MT output from our SMT, there is enough evidence to suggest PEMT could be 30% faster than human translation and 27.5% cheaper. Where we erred during our project, was creating quality metrics specific to the raw MT output and not the PEMT itself. While all our raw MT output failed to meet the standards designated by our quality metrics, it was never incomprehensible. Quality metrics designed around PEMT would better determine the amount of post-editing needed; the fewer post-edits there are the better. I could envision a scenario in which TED Talks uses SMT to mass translate all its content into other languages. Thereupon, translators could take the raw MT output and edit it to a level TED Talks deems fit.
Ultimately, training a useful SMT engine requires time to achieve good results. The key is to use time in a manner that aligns with what SMT is effective at. In order to do this, you need to ask yourself what is it that you want to translate and the translation quality that you desire to achieve.
Click here to see the slides from my group’s final presentation.