Trados Studio has an excellent Quality Checker feature that allows for a lot of flexibility and specification in what quality checks are performed, and how. As part of this, translators have the ability to input their own regex functions to search for specific errors and patterns. Here are 4 regex functions that I wrote to use in Japanese text quality checks; though some may also be useful in other target languages.
1. Add US country code
Function: Adds +1 to phone numbers in both (000)000-0000 and 000-000-0000 formats. This is a two step function.
Step 1
Find: ((\(\d{3}\))|\d{3}-)(\d{3}-\d{4}) Replace: \+1$1$3
This regex rule starts by finding US formatted phone numbers. First it looks at the area code by looking for three digits grouped together with \d{3}. US area codes can also be written with parenthesis, so we change the simple three digit search to \(\d{3}\)|]d{3}- so the rule will look for three digits with parenthesis OR three digits with no parenthesis followed by a dash. Next, the rule checks for groups of three and four digits to complete the phone number.

Inputting this Find & Replace function will change the phone number to ¥+1(000)000-0000 or ¥+1000-000-0000
Step 2
Find: (\\)(\+1)((\(\d{3}\))|\d{3}-)(\d{3}-\d{4}) Replace: $2$3$5
The second part of this function simply removes the ¥from the phone number, so you will be left with the correctly formatted phone number with the country code. It’s unclear why Trados adds the ¥symbol when the first function is run, making the second part necessary. The (\\) in the beginning of the string targets the ¥symbol, and by not including that group in the replacement string, the symbol is removed.

Inputting this Find & Replace function will change the phone number to ¥+1(000)000-0000 or ¥+1000-00Inputting this Find & Replace function will change the phone number to +1(000)000-0000 or +1000-000-0000
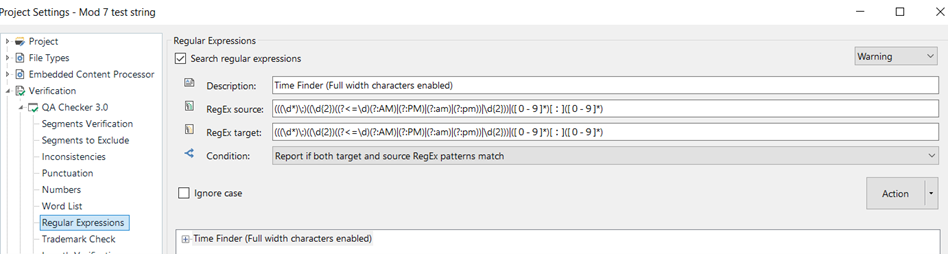
2. Time Check
Function: Finds times in am/pm formats, 24 hr format, or full-width character 24 hr format
(((\d*)\:)((\d{2})((?<=\d)(?:AM)|(?:PM)|(?:am)|(?:pm))|\d{2}))|([0-9]*)[:]([0-9]*)
Introduction
This doozy of a regex rule is designed to find expressions of time in two standard formats, and one specialized full width character format. The first standard format is a 3 or 4 digit sequence followed by AM, am, PM, or pm. For example: 7:30am. The second is a 4 digit sequence with a colon to express time in a 24 hr format. For example: 07:30 or 19:30. Numbers and symbols typed from a Japanese formatted keyboard generally produce the glyphs in full width characters. This regex rule also includes these special characters in the 24hr format sequence.
Let’s break the rule down a bit
First Half
(((\d*)\:)((\d{2})((?<=\d)(?:AM)|(?:PM)|(?:am)|\d{2}))
Here’s the first part: (((\d*)\:)((\d{2})
The rule starts by searching for 0 or more digits (\d*), then moves on to search for a colon (\:), then another two digits (\d{2}). This section would include combinations like 10:52. There’s a lot of parentheses throughout the entire rule, but they’re each important for keeping different parts of the rule organized and working together.
The next section deals with the am/pm suffixes: ((?<=\d)(?:AM)|(?:PM)|(?:am)|(?:pm))
The first part (?<=\d) is called a positive lookbehind. In this case, it’s checking to see if there’s a number before the am\pm. If there is, the rule will recognize am/pm as part of the unit of time. If it doesn’t find a number, then the rule won’t apply. This is to prevent capturing the word “am” in a sentence. The parentheses surrounding each potential am/pm each have ?: to match everything inside the parenthesis, so the rule knows to look for those two letters together, instead of separate A’s or P’s.
The final part is just looking for two more digits, in case the time is something like 13:30 and doesn’t end in am or pm. The combination \d{2} means the rule is looking for exactly two digits. Right before that, there’s a | which means the rule is looking for the entire long am\pm combination string OR just two digits.
Second Half
|([0-9]*)[:]([0-9]*)
The second half of the rule is all about finding the full width characters. First there’s a | to indicate that we’re looking for either the entire first half of the rule OR the second half. First, I used brackets to define that we’re looking for something that exactly matches the range of 0-9. The * following that range means that the rule is looking for 0 or more matches for the defined range. Next is the full width colon, then another search for more full width digits. This combination means that the rule would still accept a zero or no number in any position and include it as part of the time, like 8:20.

3. Punctuation and Quotation Mark Check
Function: Identifies cases of mistakenly included English punctuation marks in target text.
Identifying
Inputting \.|\,|“|” in the QA checker and setting it to search the target text pulls up any English punctuation marks that were left in the text. Since the target text is in Japanese, these marks should never appear.


Find and Replace
Pulling the regex rule apart into the individual punctuation marks and using the Trados’ Find and Replace feature also allows you to find all instances of the punctuation mark and judge whether or not to replace it with the equivalent Japanese punctuation mark.
4. Yen Symbol Format Check
Function: Makes sure the two Japanese yen symbols (¥/円) are placed in the correct position relative to numbers.
¥(?![0-9])|円(?=[0-9])
Identifying
There are two symbols to represent an amount of yen in Japanese: ¥ and 円. However, the ¥ symbol should only appear BEFORE the number, while 円 should only appear AFTER the number. This regex rule checks to make sure each symbol is in the right place.
First Half
¥(?![0-9])
This section uses the function (?!….), which is called a negative lookahead. This identifies the ¥symbol, then checks to see if it’s followed by a full width digit. If it does, then it’s all good. If the symbol isn’t followed by a number (implying that the number is incorrectly in front of the symbol) it will be marked as an error.
Second Half
|円(?=[0-9])
First, this part starts off with a |, meaning either/or. It’s followed by the opposite of the first half, a positive lookahead (?=….). It performs essentially the same function as the first half, but instead will check to make sure 円 is not followed by any full width digits.




