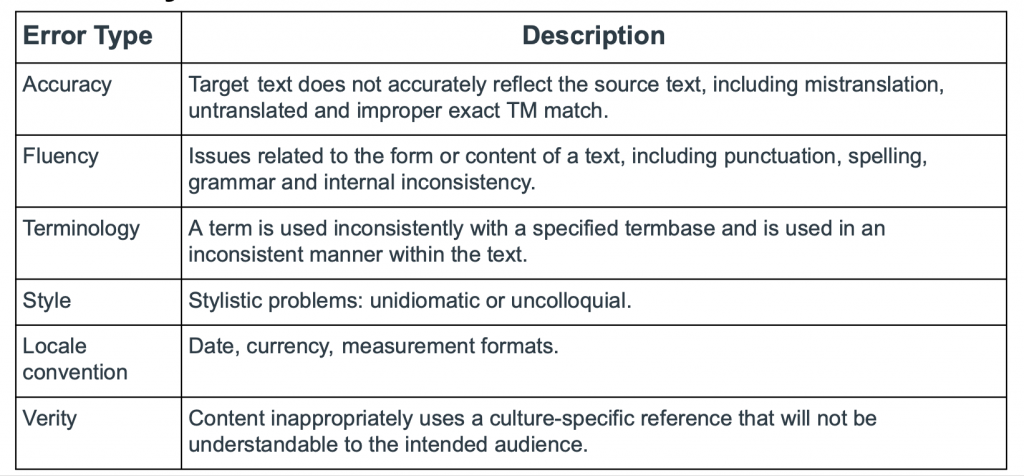
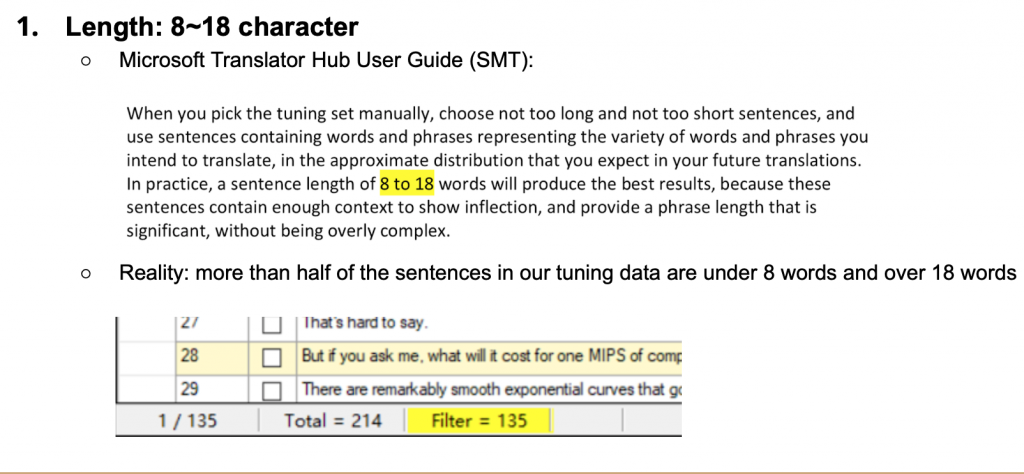
App Localization
From 2014 to 2016, I worked as an App Specialist at Apple. I reviewed a variety of apps that were in English, Spanish, French, and Portuguese. While my job did not entail actual linguistic review, I couldn’t help but be affected by my poor experience in the non-English versions on the app. Having just completed my third semester at the Middlebury Institute of International Studies (MIIS), those mistakes have become that much more obvious.
Android Studio/Xcode

When I had the opportunity to use both Android Studio and Xcode to localize two apps, I was curious to see how localization worked within both integrated development environments. For the most part, there wasn’t anything that really stood out between them. In Xcode, all strings can be exported in one step by exporting to XLIFF using Apple’s Base Internationalization. This export/import feature extracts the localizable strings to an external XLIFF file.
In Android Studio, on the other hand, there are different ways you can export text for translation, including an export to an Excel spreadsheet. For example, you can: 1) from res -> strings -> right click-> Open Translations Editor. Then copy and paste the data required from Translations Editor to excel and 2) Import the resulting Excel-based translations back into the Translation Editor.
Localizing Omni-Notes
Since I have worked with both Xcode and Android Studio, I want to discuss my experience localizing an app using Android Studio. Searching for an app that would build was a cumbersome experience in both programs. After nearly 5 hours of searching, I was ecstatic to find a workable app called Omni-Notes. After it successfully built, I realized the actual content of the app was underwhelming. As you can guess from the app name, it’s a simple note-taking app.
However, herein lies one of my first mistakes: assuming the simplicity of the app would translate to a smooth localization process. As I will get into shortly, Omni-Notes was already localized into many languages, and understanding how that process took place was key to the project’s success.
Retracing the Developers Steps
According to Android’s Localize the UI with Translations Editor, one of the first things that needs to be done is locate the strings.xml file. Each project has a default strings.xml file, which is set to a default language. In the case of my project, the default language was set to English.

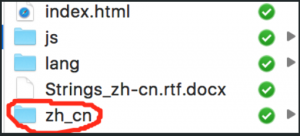
Upon discovering the strings.xml file for this project, I noticed that the app had already been localized into various languages. Fortunately, this meant instead of using hardcoded strings, this developer defined each string as a key value pair in the strings.xml file. I located the localized files by entering the resource directory for the project (see below).

When you right click on the values resource directory, you have the option to create a new values resource file. Assuming this project didn’t have any resource directories for other locales, I would create one and select a Locale from the list of qualifiers and move it into the Chosen qualifiers section by pressing the >> button in the middle of the window (see below).

Once there is a new values directory, you can right click it and create a strings.xml file for your desired locale. Since Omni-Notes was lacking a Vietnamese directory, I created one using the following steps.
Creating Omni-Notes in Vietnamese – First Steps
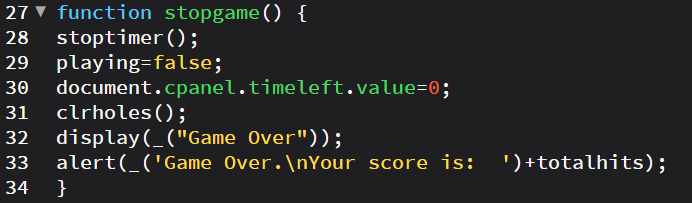
For Omni-Notes, there were two file types that I needed to localize into Vietnamese: a strings.xml file and an arrays.xml file. The biggest difference between these two file types was that the arrays.xml file contained something called a drawable. According to the Android developer website, “when you need to display static images in your app, you can use the Drawable class and its subclasses to draw shapes and images.” Given that these images were mostly universal in nature, they did not need to be localized.
For those without a CAT tool, Android does have a built-in way to translate strings called Translations Editor.
Because I have access to Memsource, using the Translation Editor would be inefficient because the translations would all have to be done manually. Using Memsource, I uploaded both the default strings.xml and arrays.xml file (English file) and used MT to translate them into Vietnamese. After downloading the completed files, I dragged them into the Vietnamese resource directory that I had created, and then I built the app again.
Takeaways
All in all, localizing in Android Studio was a manageable process. In large part, this was due to the fact that many of the strings were not hard coded and were all stored in the arrays and strings.xml files. With enough repetition, localizing in Android Studio should become easier and easier.